Следващата архитектура обяснява потока на подаване на заявка в Hive.
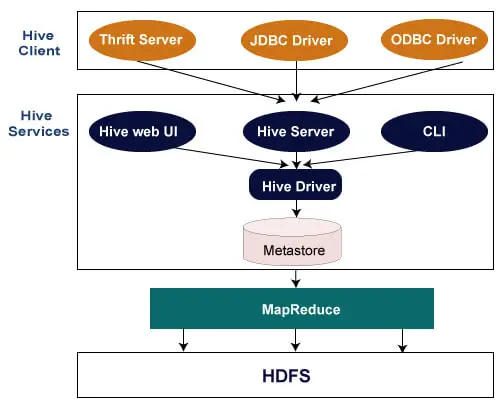
Hive клиент
Hive позволява писане на приложения на различни езици, включително Java, Python и C++. Поддържа различни типове клиенти като: -
- Thrift Server - Това е платформа за доставчик на услуги на различни езици, която обслужва заявката от всички онези езици за програмиране, които поддържат Thrift.
- JDBC драйвер - Използва се за установяване на връзка между кошер и Java приложения. JDBC драйверът присъства в класа org.apache.hadoop.hive.jdbc.HiveDriver.
- ODBC драйвер - позволява на приложенията, които поддържат ODBC протокола, да се свързват с Hive.
Hive Services
Следните са услугите, предоставяни от Hive:-
- Hive CLI - Hive CLI (Интерфейс на командния ред) е обвивка, където можем да изпълняваме заявки и команди на Hive.
- Уеб потребителски интерфейс на Hive - Уеб интерфейсът на Hive е просто алтернатива на Hive CLI. Той предоставя уеб базиран GUI за изпълнение на заявки и команди на Hive.
- Hive MetaStore - Това е централно хранилище, което съхранява цялата информация за структурата на различни таблици и дялове в склада. Той също така включва метаданни на колона и информация за нейния тип, сериализатори и десериализатори, които се използват за четене и запис на данни и съответните HDFS файлове, където се съхраняват данните.
- Hive сървър - Нарича се Apache Thrift Server. Той приема заявката от различни клиенти и я предоставя на Hive Driver.
- Hive Driver - Получава заявки от различни източници като уеб интерфейс, CLI, Thrift и JDBC/ODBC драйвер. Той прехвърля заявките към компилатора.
- Hive Compiler – Целта на компилатора е да анализира заявката и да извърши семантичен анализ на различните блокове и изрази на заявката. Той преобразува HiveQL изрази в задачи на MapReduce.
- Hive Execution Engine - Optimizer генерира логическия план под формата на DAG от задачи за намаляване на картата и HDFS задачи. В крайна сметка механизмът за изпълнение изпълнява входящите задачи в реда на техните зависимости.