Клъстерирането или клъстерният анализ е техника за машинно обучение, която групира немаркирания набор от данни. Може да се определи като „Начин за групиране на точките от данни в различни клъстери, състоящи се от подобни точки от данни. Обектите с възможни прилики остават в група, която има по-малко или никакви прилики с друга група.'
Прави го, като намира някои подобни модели в немаркирания набор от данни, като форма, размер, цвят, поведение и т.н., и ги разделя според наличието и отсъствието на тези подобни модели.
Това е обучение без надзор метод, следователно не се предоставя надзор на алгоритъма и той се занимава с немаркирания набор от данни.
След прилагане на тази техника за клъстериране, всеки клъстер или група се предоставя с клъстер-ID. ML системата може да използва този идентификатор, за да опрости обработката на големи и сложни набори от данни.
Техниката за групиране обикновено се използва за анализ на статистически данни.
Забележка: Клъстерирането е някъде подобно на класификационен алгоритъм , но разликата е типът набор от данни, който използваме. При класификацията работим с етикетирания набор от данни, докато при клъстерирането работим с немаркирания набор от данни.
Пример : Нека разберем техниката за клъстериране с примера от реалния свят на Mall: Когато посетим търговски център, можем да наблюдаваме, че нещата с подобна употреба са групирани заедно. Например тениските са групирани в една секция, а панталоните са в други секции, по същия начин в секциите със зеленчуци, ябълки, банани, манго и т.н. са групирани в отделни секции, така че лесно да можем да открием нещата. Техниката за групиране също работи по същия начин. Други примери за клъстериране са групирането на документи според темата.
Техниката за групиране може да се използва широко в различни задачи. Някои от най-честите употреби на тази техника са:
- Сегментиране на пазара
- Анализ на статистически данни
- Анализ на социални мрежи
- Сегментиране на изображението
- Откриване на аномалии и др.
Освен тези общи употреби, той се използва от Amazon в своята система за препоръки, за да предостави препоръките според миналото търсене на продукти. Нетфликс също използва тази техника, за да препоръчва филмите и уеб сериалите на своите потребители според хронологията на гледане.
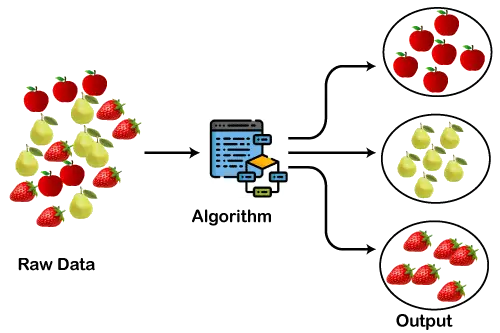
Диаграмата по-долу обяснява работата на алгоритъма за клъстериране. Виждаме, че различните плодове са разделени на няколко групи с подобни свойства.
Видове методи за групиране
Методите за клъстериране са широко разделени на Твърдо клъстериране (точката от данни принадлежи само към една група) и Меко клъстериране (точките с данни могат да принадлежат и към друга група). Но съществуват и други различни подходи за групиране. По-долу са основните методи за клъстериране, използвани в машинното обучение:
Клъстериране на дялове
Това е вид групиране, което разделя данните на не-йерархични групи. Известен е още като метод, базиран на центроид . Най-често срещаният пример за разделяне на клъстери е K-Means Алгоритъм за групиране .
При този тип наборът от данни е разделен на набор от k групи, където K се използва за определяне на броя на предварително дефинираните групи. Центърът на клъстера е създаден по такъв начин, че разстоянието между точките с данни на един клъстер е минимално в сравнение с центроида на друг клъстер.
прочетете csv файла в java

Клъстериране на базата на плътност
Методът за клъстериране, базиран на плътност, свързва областите с висока плътност в клъстери и разпределенията с произволна форма се формират, докато плътният регион може да бъде свързан. Този алгоритъм го прави, като идентифицира различни клъстери в набора от данни и свързва областите с висока плътност в клъстери. Плътните области в пространството за данни са разделени една от друга от по-редки области.
Тези алгоритми могат да се сблъскат с трудности при клъстерирането на точките от данни, ако наборът от данни има различна плътност и високи размери.

Клъстериране, базирано на модел на разпространение
При метода за клъстериране, базиран на модел на разпределение, данните се разделят въз основа на вероятността как даден набор от данни принадлежи към конкретно разпределение. Групирането се извършва чрез приемане на някои общи разпределения Разпределение на Гаус .
Пример за този тип е Алгоритъм за групиране на очаквания-максимизиране който използва смесени модели на Гаус (GMM).

Йерархично групиране
Йерархичното клъстериране може да се използва като алтернатива на разделеното клъстериране, тъй като няма изискване за предварително уточняване на броя на клъстерите, които да бъдат създадени. При тази техника наборът от данни се разделя на клъстери, за да се създаде дървовидна структура, която също се нарича a дендрограма . Наблюденията или произволен брой клъстери могат да бъдат избрани чрез изрязване на дървото на правилното ниво. Най-често срещаният пример за този метод е Агломеративен йерархичен алгоритъм .

Размито клъстериране
Размитото групиране е вид мек метод, при който даден обект с данни може да принадлежи към повече от една група или клъстер. Всеки набор от данни има набор от коефициенти на членство, които зависят от степента на членство в клъстер. Алгоритъм за размити C-средства е примерът за този тип групиране; понякога е известен също като алгоритъм на Fuzzy k-средни стойности.
Алгоритми за групиране
Алгоритмите за клъстериране могат да бъдат разделени въз основа на техните модели, които са обяснени по-горе. Има публикувани различни типове алгоритми за клъстериране, но само няколко от тях се използват често. Алгоритъмът за клъстериране се основава на вида данни, които използваме. Като например, някои алгоритми трябва да отгатнат броя на клъстерите в даден набор от данни, докато някои трябва да намерят минималното разстояние между наблюдението на набора от данни.
Тук обсъждаме предимно популярни алгоритми за клъстериране, които се използват широко в машинното обучение:
Приложения на клъстерирането
По-долу са някои често известни приложения на техниката за клъстериране в машинното обучение: