Преди да разберем разликите между линейното и двоичното търсене, първо трябва да знаем линейното търсене и двоичното търсене поотделно.
Какво е линейно търсене?
Линейното търсене е известно също като последователно търсене, което просто сканира всеки елемент наведнъж. Да предположим, че искаме да търсим елемент в масив или списък; просто изчисляваме дължината му и не скачаме върху нито един елемент.
Нека разгледаме един прост пример.
Да предположим, че имаме масив от 10 елемента, както е показано на фигурата по-долу:
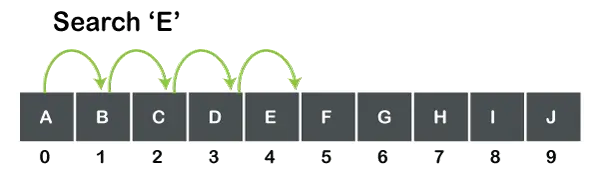
Фигурата по-горе показва масив от символен тип с 10 стойности. Ако искаме да търсим 'E', тогава търсенето започва от 0thелемент и сканира всеки елемент, докато елементът, т.е. „E“, не бъде намерен. Не можем директно да скочим от 0thелемент към 4thелемент, т.е. всеки елемент се сканира един по един, докато елементът не бъде намерен.
Сложност на линейното търсене
Тъй като линейното търсене сканира всеки елемент един по един, докато елементът не бъде намерен. Ако броят на елементите се увеличи, броят на елементите за сканиране също се увеличава. Можем да кажем, че времето, необходимо за търсене на елементите, е пропорционално на броя на елементите . Следователно сложността в най-лошия случай е O(n)
Какво е двоично търсене?
Двоичното търсене е търсене, при което средният елемент се изчислява, за да се провери дали е по-малък или по-голям от елемента, който трябва да се търси. Основното предимство на използването на двоично търсене е, че то не сканира всеки елемент в списъка. Вместо да сканира всеки елемент, той извършва търсене до половината от списъка. Така че двоичното търсене отнема по-малко време за търсене на елемент в сравнение с линейното търсене.
Единственият предпоставка за двоично търсене е, че масивът трябва да бъде в сортиран ред, докато линейното търсене работи както върху сортиран, така и върху несортиран масив. Алгоритъмът за двоично търсене се основава на техниката разделяй и владей, което означава, че ще разделя масива рекурсивно.
Има три случая, използвани в двоичното търсене:
Случай 1: данни
Случай 2: data>a[mid] след това дясно=mid-1
Случай 3: data = a[mid] // е намерен елемент
В горния случай, ' а ' е името на масива, средата е индексът на елемента, изчислен рекурсивно, данни е елементът, който трябва да се търси, наляво обозначава левия елемент на масива и точно обозначава елемента, който се намира от дясната страна на масива.
Нека разберем работата на двоичното търсене чрез пример.
Да предположим, че имаме масив с размер 10, който е индексиран от 0 до 9, както е показано на фигурата по-долу:
Искаме да търсим 70 елемента от горния масив.
Етап 1: Първо изчисляваме средния елемент на масив. Разглеждаме две променливи, т.е. ляво и дясно. Първоначално ляво =0 и дясно=9, както е показано на фигурата по-долу:

Стойността на средния елемент може да се изчисли като:

Следователно mid = 4 и a[mid] = 50. Елементът, който трябва да се търси, е 70, така че a[mid] не е равно на данни. Случай 2 е удовлетворен, т.е. data>a[mid].

Стъпка 2: Като data>a[mid], така че стойността на left се увеличава с mid+1, т.е. left=mid+1. Стойността на mid е 4, така че стойността на left става 5. Сега имаме подмасив, както е показано на фигурата по-долу:

Сега отново средната стойност се изчислява с помощта на горната формула и стойността на mid става 7. Сега средната стойност може да бъде представена като:

На фигурата по-горе можем да наблюдаваме, че a[mid]>data, така че отново стойността на mid ще бъде изчислена в следващата стъпка.
Стъпка 3: Като [mid]>данни, стойността на right се намалява с mid-1. Стойността на mid е 7, така че стойността на right става 6. Масивът може да бъде представен като:

Стойността на mid ще бъде изчислена отново. Стойностите на ляво и дясно са съответно 5 и 6. Следователно стойността на mid е 5. Сега mid може да бъде представена в масив, както е показано по-долу:

На фигурата по-горе можем да наблюдаваме, че [среда]
Стъпка 4: като [среда] Сега стойността на mid се изчислява отново с помощта на формулата, която вече обсъдихме. Стойностите на ляво и дясно са съответно 6 и 6, така че стойността на средата става 6, както е показано на фигурата по-долу: Можем да видим на горната фигура, че a[mid]=data. Следователно търсенето е завършено и елементът е намерен успешно. Следните са разликите между линейното търсене и двоичното търсене: Описание Линейното търсене е търсене, което намира елемент в списъка, като търси елемента последователно, докато елементът бъде намерен в списъка. От друга страна, двоичното търсене е търсене, което намира средния елемент в списъка рекурсивно, докато средният елемент не бъде съпоставен с търсен елемент. Работят и двете търсения Линейното търсене започва да търси от първия елемент и сканира един по един елемент, без да прескача към следващия елемент. От друга страна, двоичното търсене разделя масива наполовина, като изчислява средния елемент на масива. Внедряване Линейното търсене може да се приложи върху всяка линейна структура от данни като вектор, единично свързан списък, двойно свързан списък. Обратно, двоичното търсене може да се приложи върху тези структури от данни с двупосочно преминаване, т.е. преминаване напред и назад. Сложност Линейното търсене е лесно за използване или можем да кажем, че е по-малко сложно, тъй като елементите за линейно търсене могат да бъдат подредени в произволен ред, докато при двоично търсене елементите трябва да бъдат подредени в определен ред. Сортирани елементи Елементите за линейно търсене могат да бъдат подредени в произволен ред. При линейното търсене не е задължително елементите да са подредени в сортиран ред. От друга страна, при двоично търсене елементите трябва да бъдат подредени в сортиран ред. Тя може да бъде подредена във възходящ или в низходящ ред и съответно алгоритъмът ще бъде променен. Тъй като двоичното търсене използва сортиран масив, е необходимо елементът да се вмъкне на правилното място. За разлика от това, линейното търсене не се нуждае от сортиран масив, така че новият елемент може лесно да бъде вмъкнат в края на масива. Приближаване Линейното търсене използва итеративен подход за намиране на елемента, така че е известно също като последователен подход. За разлика от това, двоичното търсене изчислява средния елемент на масива, така че използва подхода разделяй и владей. Набор от данни Линейното търсене не е подходящо за голям набор от данни. Ако искаме да търсим елемента, който е последният елемент от масива, линейното търсене ще започне да търси от първия елемент и ще продължи до последния елемент, така че времето, необходимо за търсене на елемента, ще бъде голямо. От друга страна, двоичното търсене е подходящо за голям набор от данни, тъй като отнема по-малко време. Скорост Ако наборът от данни е голям при линейно търсене, тогава изчислителната цена ще бъде висока и скоростта става ниска. Ако наборът от данни е голям при двоично търсене, тогава изчислителната цена ще бъде по-малка в сравнение с линейното търсене и скоростта става висока. Размери Линейното търсене може да се използва както в едномерен, така и в многомерен масив, докато двоичното търсене може да се приложи само в едномерен масив. Ефективност Линейното търсене е по-малко ефективно, когато вземем предвид големите набори от данни. Двоичното търсене е по-ефективно от линейното търсене в случай на големи набори от данни. Нека да разгледаме разликите в таблична форма. 
Разлики между линейно търсене и двоично търсене

нормални форми
База за сравнение Линейно търсене Двоично търсене Определение Линейното търсене започва да търси от първия елемент и сравнява всеки елемент с търсен елемент, докато елементът не бъде намерен. Той намира позицията на търсения елемент, като намира средния елемент на масива. Сортирани данни При линейно търсене не е необходимо елементите да бъдат подредени в сортиран ред. Предварителното условие за двоичното търсене е елементите да бъдат подредени в сортиран ред. Внедряване Линейното търсене може да се приложи върху всяка линейна структура от данни като масив, свързан списък и др. Прилагането на двоично търсене е ограничено, тъй като може да се приложи само върху онези структури от данни, които имат двупосочно преминаване. Приближаване Базира се на последователния подход. Основава се на подхода „разделяй и владей“. Размер За предпочитане е за малки масиви от данни. За предпочитане е за масиви от данни с голям размер. Ефективност Той е по-малко ефективен в случай на масиви от данни с голям размер. Той е по-ефективен в случай на масиви от данни с голям размер. В най-лошия случай При линейно търсене най-лошият сценарий за намиране на елемента е O(n). При двоично търсене най-лошият сценарий за намиране на елемента е O(log2н). Най-добрият сценарий При линейно търсене най-добрият сценарий за намиране на първия елемент в списъка е O(1). При двоично търсене най-добрият сценарий за намиране на първия елемент в списъка е O(1). Размерен масив Може да се реализира както върху едномерен, така и върху многомерен масив. Може да се реализира само върху многомерен масив.