Командата Linux uniq се използва за премахване на всички повтарящи се редове от файл. Също така може да се използва за показване на броя на всяка дума, само на повтарящи се редове, игнориране на знаци и сравняване на конкретни полета. Това е една от най-често използваните команди в Linux система. Често се използва с команда за сортиране защото сравнява съседни знаци. Той отхвърля всички идентични редове и записва изхода.
Синтаксис:
uniq [OPTION]... [INPUT [OUTPUT]]
Настроики:
Някои полезни опции на командния ред на командата uniq са следните:
-c, --брой: той префиксира редовете според броя на срещанията.
-d, --повторено: използва се за отпечатване на дублирани редове, по един за всяка група.
-Д: Използва се за отпечатване на всички дублирани редове.
--all-repeated[=МЕТОД]: Тя е доста подобна на опцията '-D', разликата между двете опции е, че позволява разделяне на групи с празен ред.
-f, --skip-fields=N: Използва се, за да се избегне сравнението на първите N полета.
--group[=МЕТОД]: Използва се за показване на всички елементи и разделя групите с празен ред.
-i, --ignore-case: Използва се за игнориране на разликите при сравняване.
-s, --skip-chars=N: Използва се, за да се избегне сравнението на първите N знака.
-u, --уникален: използва се за отпечатване на уникални линии.
-z, --завършва с нула: Използва се за разделител на редове, който е NUL, а не режим на нов ред.
какво е svn checkout
-w, --check-chars=N: Използва се за сравняване на не повече от N знака в редове.
--помогне: Използва се за показване на помощна документация.
--версия: Използва се за показване на информация за версията.
Примери за уникална команда
Нека видим следните примери за командата uniq:
- Премахнете повтарящите се редове
- пребройте броя на срещанията на една дума
- Показване на повтарящите се редове
- Покажете уникалните линии
- Игнорирайте знаците при сравнение
- Игнориране на полета при сравнение
Премахнете повтарящите се редове
За да премахнете повтарящи се редове от файл, изпълнете основната команда uniq, както следва:
sort dupli.txt | uniq
Горната команда ще премахне дублиращите се редове от файла „dupli.txt“. Помислете за резултата по-долу:
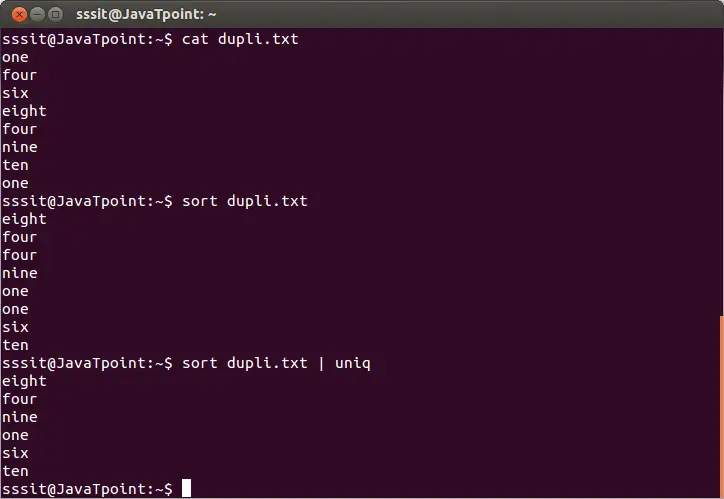
От горния резултат повтарящите се думи се игнорират.
Пребройте броя на срещанията на една дума
Можем да преброим броя на срещанията на дума, като използваме командата uniq. Опцията '-c' се използва за преброяване на думата. Изпълнете го по следния начин:
sort dupli.txt | uniq -c
Горната команда ще преброи думите, които влизат в „dupli.txt“. Помислете за резултата по-долу:

От горния резултат командата 'sort dupli.txt | uniq -c' отчита колко пъти една дума се повтаря.
Показване на повтарящите се редове
Опцията '-d' се използва за показване само на повтарящите се редове. Той ще покаже само редовете, които ще бъдат повече от веднъж във файл и ще запише изхода в стандартния изход. Помислете за командата по-долу:
sort dupli.txt | uniq -d
Горната команда ще покаже само повтарящите се редове. Помислете за резултата по-долу:

Покажете уникалните линии
Опцията '-u' се използва за показване само на уникалните редове (които не се повтарят). Той ще покаже само редовете, които се срещат само веднъж, и ще запише резултата в стандартния изход. Помислете за командата по-долу:
sort dupli.txt | uniq -u
Горната команда ще покаже само уникалните редове от файла „dupli.txt“. Помислете за резултата по-долу:

Игнорирайте знаците при сравнение
Опцията '-s' се използва за игнориране на знаците при сравнение. Той ще игнорира посочения брой знаци и ще покаже резултата на стандартния изход. Помислете за командата по-долу:
sort dupli.txt | uniq -s 2
Горната команда ще игнорира първите два знака при сравнение от файла „dupli.txt“. Помислете за резултата по-долу:

Игнориране на полета при сравнение
Опцията '-f' се използва за игнориране на полетата. Помислете за командата по-долу:
uniq -f 2 dupli2.txt
Горната команда няма да сравни първите две полета от файла „dupli2.txt“. Помислете за резултата по-долу:

От горния резултат първите две полета се пропускат, а останалите полета се сравняват от файла „dupli2.txt“.