Ние четем линейните структури от данни като масив, свързан списък, стек и опашка, в които всички елементи са подредени по последователен начин. Различните структури от данни се използват за различни видове данни.
При избора на структурата на данните се вземат предвид някои фактори:
Дърво също е една от структурите от данни, които представляват йерархични данни. Да предположим, че искаме да покажем служителите и техните позиции в йерархична форма, тогава тя може да бъде представена, както е показано по-долу:
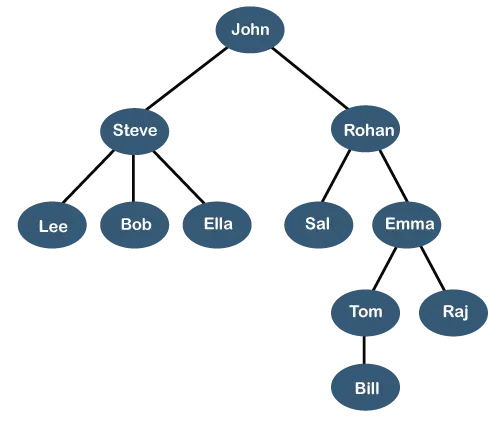
Горното дърво показва организационна йерархия на някаква компания. В горната структура, Джон е изпълнителен директор на компанията, а Джон има двама преки докладчици, наречени като Стив и Рохан . Стив има трима имена на преки докладчици Лий, Боб, Ела където Стив е управител. Боб има два имена на преки докладчици трябва и Ема . Ема има двама имена на преки докладчици Том и Радж . Том има един пряк докладчик на име Бил . Тази конкретна логическа структура е известна като a Дърво . Структурата му е подобна на истинското дърво, затова е наречена a Дърво . В тази структура, корен е на върха, а клоните му се движат в посока надолу. Следователно можем да кажем, че структурата на данните на дървото е ефективен начин за съхранение на данните по йерархичен начин.
Нека разберем някои ключови моменти от структурата на данните на дървото.
- Дървовидната структура на данни се дефинира като колекция от обекти или обекти, известни като възли, които са свързани заедно, за да представят или симулират йерархия.
- Дървовидната структура от данни е нелинейна структура от данни, тъй като не се съхранява по последователен начин. Това е йерархична структура, тъй като елементите в дървото са подредени на множество нива.
- В структурата на данните на дървото най-горният възел е известен като основен възел. Всеки възел съдържа някои данни и данните могат да бъдат от всякакъв тип. В горната дървовидна структура възелът съдържа името на служителя, така че типът данни ще бъде низ.
- Всеки възел съдържа някои данни и връзка или препратка към други възли, които могат да бъдат наречени дъщерни.
Някои основни термини, използвани в дървовидната структура на данните.
Нека разгледаме дървовидната структура, която е показана по-долу:

В горната структура всеки възел е обозначен с някакъв номер. Всяка стрелка, показана на горната фигура, е известна като a връзка между двата възела.
Свойства на дървовидната структура от данни

Въз основа на свойствата на структурата от данни на дървото дърветата се класифицират в различни категории.
Внедряване на дърво
Дървовидната структура от данни може да бъде създадена чрез динамично създаване на възлите с помощта на указателите. Дървото в паметта може да бъде представено, както е показано по-долу:

Фигурата по-горе показва представянето на дървовидната структура от данни в паметта. В горната структура възелът съдържа три полета. Второто поле съхранява данните; първото поле съхранява адреса на лявото дете, а третото поле съхранява адреса на дясното дете.
рохит шети актьор
В програмирането структурата на възел може да се дефинира като:
struct node { int data; struct node *left; struct node *right; } Горната структура може да бъде дефинирана само за двоичните дървета, тъй като двоичното дърво може да има най-много две деца, а генеричните дървета могат да имат повече от две деца. Структурата на възела за генерични дървета би била различна в сравнение с двоичното дърво.
Приложения на дървета
Следните са приложенията на дърветата:
Типове дървовидна структура от данни
Следват типовете дървовидна структура от данни:

Може да има н брой поддървета в общо дърво. В общото дърво поддърветата не са подредени, тъй като възлите в поддървото не могат да бъдат подредени.
Всяко непразно дърво има низходящ ръб и тези ръбове са свързани с възлите, известни като дъщерни възли . Основният възел е обозначен с ниво 0. Възлите, които имат един и същ родител, са известни като братя и сестри .

За да научите повече за двоичното дърво, щракнете върху връзката, дадена по-долу:
https://www.javatpoint.com/binary-tree
Всеки възел в лявото поддърво трябва да съдържа стойност, по-малка от стойността на основния възел, а стойността на всеки възел в дясното поддърво трябва да бъде по-голяма от стойността на основния възел.
Възел може да бъде създаден с помощта на дефиниран от потребителя тип данни, известен като структура, както е показано по-долу:
struct node { int data; struct node *left; struct node *right; } Горното е структурата на възела с три полета: поле за данни, второто поле е левият указател на типа възел, а третото поле е десният указател на типа възел.
За да научите повече за двоичното дърво за търсене, щракнете върху връзката, дадена по-долу:
https://www.javatpoint.com/binary-search-tree
Това е един от видовете на двоичното дърво или можем да кажем, че е вариант на двоичното дърво за търсене. AVL дървото удовлетворява свойството на двоично дърво както и на двоично дърво за търсене . Това е самобалансиращо се двоично дърво за търсене, което е изобретено от Аделсън Велски Линдас . Тук самобалансирането означава балансиране на височините на лявото поддърво и дясното поддърво. Това балансиране се измерва по отношение на балансиращ фактор .
java enums
Можем да разглеждаме едно дърво като AVL дърво, ако дървото се подчинява на дървото за двоично търсене, както и на балансиращ фактор. Балансиращият фактор може да се определи като разлика между височината на лявото поддърво и височината на дясното поддърво . Стойността на балансиращия фактор трябва да бъде 0, -1 или 1; следователно всеки възел в AVL дървото трябва да има стойността на балансиращия фактор като 0, -1 или 1.
За да научите повече за AVL дървото, щракнете върху връзката, дадена по-долу:
https://www.javatpoint.com/avl-tree
Червено-черното дърво е дървото за двоично търсене. Предпоставката за червено-черното дърво е, че трябва да знаем за двоичното дърво за търсене. В дърво за двоично търсене стойността на лявото поддърво трябва да бъде по-малка от стойността на този възел, а стойността на дясното поддърво трябва да бъде по-голяма от стойността на този възел. Както знаем, времевата сложност на двоичното търсене в средния случай е log2n, най-добрият случай е O(1), а най-лошият случай е O(n).
Когато се извършва каквато и да е операция върху дървото, ние искаме нашето дърво да бъде балансирано, така че всички операции като търсене, вмъкване, изтриване и т.н. да отнемат по-малко време и всички тези операции ще имат времевата сложност на дневник2н.
Червено-черното дърво е самобалансиращо се двоично дърво за търсене. Тогава AVL дървото също е дърво за двоично търсене с балансиране на височината защо се нуждаем от червено-черно дърво . В AVL дървото не знаем колко завъртания ще са необходими за балансиране на дървото, но в червено-черното дърво са необходими максимум 2 завъртания за балансиране на дървото. Той съдържа един допълнителен бит, който представлява червения или черния цвят на възел, за да се гарантира балансирането на дървото.
Дървовидната структура на данните за разкривяване също е двоично дърво за търсене, в което наскоро достъпният елемент се поставя в основната позиция на дървото чрез извършване на някои ротационни операции. Тук, разпръскване означава наскоро достъпения възел. Това е самобалансиране двоично дърво за търсене без изрично условие за баланс като AVL дърво.
Възможно е височината на разкривеното дърво да не е балансирана, т.е. височината както на лявото, така и на дясното поддървета може да се различава, но операциите в разкривеното дърво са в ред спокоен време къде н е броят на възлите.
Splay tree е балансирано дърво, но не може да се разглежда като балансирано по височина дърво, тъй като след всяка операция се извършва завъртане, което води до балансирано дърво.
Структурата на данните Treap идва от структурата на данните Tree и Heap. И така, той включва свойствата както на дървовидните, така и на купчините структури от данни. В дървото за двоично търсене всеки възел в лявото поддърво трябва да бъде равен или по-малък от стойността на основния възел, а всеки възел в дясното поддърво трябва да бъде равен или по-голям от стойността на основния възел. В структурата на купчини данни и дясното, и лявото поддървета съдържат по-големи ключове от корена; следователно можем да кажем, че коренният възел съдържа най-ниската стойност.
В структурата на данните на treap всеки възел има и двете ключ и приоритет където ключът се извлича от двоичното дърво за търсене, а приоритетът се извлича от структурата на данните на купчината.
низ към int java
The треп структурата на данните следва две свойства, които са дадени по-долу:
- Дясно дете на възел>=текущ възел и ляво дете на възел<=current node (binary tree)< li>
- Децата на всяко поддърво трябва да са по-големи от възела (купчина)
B-дървото е балансирано м-начин дърво къде м определя реда на дървото. Досега четем, че възелът съдържа само един ключ, но b-дървото може да има повече от един ключ и повече от 2 деца. Той винаги поддържа сортираните данни. В двоичното дърво е възможно листните възли да са на различни нива, но в b-дървото всички листови възли трябва да са на едно и също ниво.
Ако редът е m, тогава възелът има следните свойства:
- Всеки възел в b-дърво може да има максимум м деца
- За минимум деца листовият възел има 0 деца, коренният възел има минимум 2 деца и вътрешният възел има минимален таван от m/2 деца. Например стойността на m е 5, което означава, че един възел може да има 5 деца, а вътрешните възли могат да съдържат максимум 3 деца.
- Всеки възел има максимум (m-1) ключове.
Основният възел трябва да съдържа минимум 1 ключ, а всички останали възли трябва да съдържат най-малко таван m/2 минус 1 ключове.